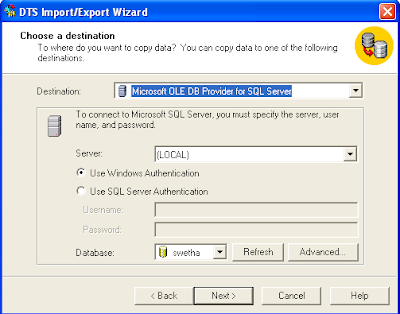
Normalization is the process of efficiently organizing data in a database. Goals: eliminating redundant data (for example, storing the same data in more than one table) ensuring data dependencies make sense (only storing related data in a table) Levels: 1 NF, 2NF, 3NF, BCNF (Boyce-Codd Normal Form), 4NF, 5 NF 1 NF: Eliminate duplicative columns from the same table. Create separate tables for each group of related data and identify each row with a unique column or set of columns (the primary key).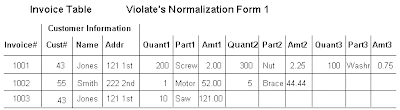 2 NF: Meet all the requirements of the first normal form. Remove subsets of data that apply to multiple rows of a table and place them in separate tables. Create relationships between these new tables and their predecessors through the use of foreign keys.
2 NF: Meet all the requirements of the first normal form. Remove subsets of data that apply to multiple rows of a table and place them in separate tables. Create relationships between these new tables and their predecessors through the use of foreign keys.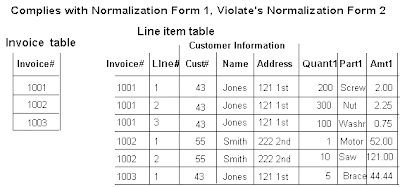
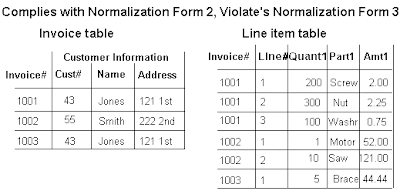
3 NF: Meet all the requirements of the second normal form. Remove columns that are not dependent upon the primary key. Eg: total, average etc which can be calculated in sql query

Boyce-Codd NF:
A relation is in Boyce-Codd Normal Form (BCNF) if every determinant is a candidate key.
OR
Key attribute should not depend on a non key attribute.
Determinant: A determinant in a database table is any attribute that you can use to determine the values assigned to other attribute(s) in the same row.
Examples: Consider a table with the attributes employee_id, first_name, last_name and date_of_birth. In this case, the field employee_id determines the remaining three fields. The name fields do not determine the employee_id because the firm may have more than one employee with the same first and/or last name. Similarly, the DOB field does not determine the employee_id or the name fields because more than one employee may share the same birthday.
Candidate Key: A candidate key is a combination of attributes that can be uniquely used to identify a database record. Each table may have one or more candidate keys. One of these candidate keys is selected as the table primary key.
4 NF:
Meet all the requirements of the third normal form and BCNF.
A relation is in 4NF if it has no more than one multi-valued or multiple dependency.Consider these entities: employees, skills, and languages. An employee can have several skills and know several languages. There are two relationships, one between employees and skills, and one between employees and languages. A table is not in fourth normal form if it represents both relationships. Instead, the relationships should be represented in two tables. If, however, the attributes are interdependent (that is, the employee applies certain languages only to certain skills), the table should not be split.A good strategy when designing a database is to arrange all data in tables that are in fourth normal form, and then to decide whether the results give you an acceptable level of performance. If they do not, you can rearrange the data in tables that are in third normal form, and then re assess performance.
5NF:
(join-projection normal form)JPNF
It should be in 4NF.
No multi valued dependency exists.