Thursday, September 4, 2008
SQL Order By our specific order
Generally we can get the records in alphabetical or numeric order by default either in ascending or descending by specifying ORDER BY clause in the query. But sometimes in our applications, we may need to get the records in a specific order. For example, the order of names that we get from the database needs to be displayed in an order other than A to Z or Z to A. Here is the solution that i found.
Example:
Suppose that there is a query like below:
select * from emp where empname in ('B1','A1','C1')
You want the records to be displayed in the same order as above. Then change the query as below.
select * from emp
where empname in ('B1','A1','C1')
order by CASE empname
WHEN 'B1' THEN 1
WHEN 'A1' THEN 2
WHEN 'C1' THEN 3
END
Thursday, August 7, 2008
REPLICATE function
Repeats a string value a specified number of times.
Syntax:
REPLICATE ( string , integer)
string - what should be repeated or added
integer - how many times string value should be repeated
Example:
select REPLICATE('0',2)+[Product_Code] from Products
The above query will return the product code value with 2 zeroes added at the first.
If product code is PCT then the result will be 00PCT
Syntax:
REPLICATE ( string , integer)
string - what should be repeated or added
integer - how many times string value should be repeated
Example:
select REPLICATE('0',2)+[Product_Code] from Products
The above query will return the product code value with 2 zeroes added at the first.
If product code is PCT then the result will be 00PCT
Thursday, May 29, 2008
Import Data from excel file to MSSQL database
Steps to import data from excel to the database:
Step 1: Go to Sql Server Enterprise Manager > Right click on local database server > All Tasks > Import Data

Step 2: A screen appears like below. Click Next

Step 3: Select Microsoft Excel option in Data Source, Browse and select the file and clilck Next

Step 4: Select the destination database name and click Next
Step 5: Select the database using check box which is provided and click Next.
Note: This process will automatically create a new table if the table does not exists.

Step 6: A screen appears like below. Click Next.

Step 7: Check Run immediately (default). Click Next.

Step 8: An alert is given after succesfully copying the data. Click OK.

Step 9: Click Done

Step 10: Click Finish

Tags: Import Data from excel file to MSSQL database, Excel Data to Sql server database, Export Data from sql server to excel file
Step 1: Go to Sql Server Enterprise Manager > Right click on local database server > All Tasks > Import Data
Step 2: A screen appears like below. Click Next
Step 3: Select Microsoft Excel option in Data Source, Browse and select the file and clilck Next
Step 4: Select the destination database name and click Next
Step 5: Select the database using check box which is provided and click Next.
Note: This process will automatically create a new table if the table does not exists.
Step 6: A screen appears like below. Click Next.
Step 7: Check Run immediately (default). Click Next.
Step 8: An alert is given after succesfully copying the data. Click OK.
Step 9: Click Done
Step 10: Click Finish

Tags: Import Data from excel file to MSSQL database, Excel Data to Sql server database, Export Data from sql server to excel file
Tuesday, May 20, 2008
Important SQL Queries, Important Database Queries
To find the nth row of a table
In oracle:
Select * from emp where rowid = (select max(rowid) from emp where rownum <= 4)
In Sql Server 2005:
Select * from emp where rowid = (select max(rowid) from emp where row_number() <= 4)
To find duplicate rows
Select * from emp where rowid in (select max(rowid) from emp group by empno, ename, mgr, job, hiredate, comm, deptno, sal)
To delete duplicate rows
Delete emp where rowid in (select max(rowid) from emp group by empno,ename,mgr,job,hiredate,sal,comm,deptno)
To find the count of duplicate rows
Select ename, count(*) from emp group by ename having count(*) >= 1
To display alternative rows in a table
In oracle:
select * from emp where (rowid,0) in (select rowid,mod(rownum,2) from emp)
Getting employee details of each department who is drawing maximum sal
select * from emp where (deptno,sal) in ( select deptno,max(sal) from emp group by deptno)
To get number of employees in each department, in which department is having more than 2500 employees
Select deptno,count(*) from emp group by deptno having count(*) >2500
To find nth maximum sal
In oracle:
Select * from emp where sal in (select max(sal) from (select * from emp order by sal) where rownum <= 5)
If you have to give a flat hike to your EMPloyee using the Following CriteriaSalary b/w 2000 and 3000 then Hike is 200Salary b/w 3000 and 4000 then Hike is 300 Salary b/w 4000 and 5000 then Hike is 400 in EMPLOYEE Table
Update EMPLOYEE Set Salary =
In oracle:
Select * from emp where rowid = (select max(rowid) from emp where rownum <= 4)
In Sql Server 2005:
Select * from emp where rowid = (select max(rowid) from emp where row_number() <= 4)
To find duplicate rows
Select * from emp where rowid in (select max(rowid) from emp group by empno, ename, mgr, job, hiredate, comm, deptno, sal)
To delete duplicate rows
Delete emp where rowid in (select max(rowid) from emp group by empno,ename,mgr,job,hiredate,sal,comm,deptno)
To find the count of duplicate rows
Select ename, count(*) from emp group by ename having count(*) >= 1
To display alternative rows in a table
In oracle:
select * from emp where (rowid,0) in (select rowid,mod(rownum,2) from emp)
Getting employee details of each department who is drawing maximum sal
select * from emp where (deptno,sal) in ( select deptno,max(sal) from emp group by deptno)
To get number of employees in each department, in which department is having more than 2500 employees
Select deptno,count(*) from emp group by deptno having count(*) >2500
To find nth maximum sal
In oracle:
Select * from emp where sal in (select max(sal) from (select * from emp order by sal) where rownum <= 5)
If you have to give a flat hike to your EMPloyee using the Following CriteriaSalary b/w 2000 and 3000 then Hike is 200Salary b/w 3000 and 4000 then Hike is 300 Salary b/w 4000 and 5000 then Hike is 400 in EMPLOYEE Table
Update EMPLOYEE Set Salary =
Case when Salary between 2000 and 3000 then
Salary = Salary+200
Case when Salary between 3000 and 4000 then
Salary = Salary+300
Case when Salary between 3000 and 4000 then
Salary = Salary+300
End
Tags: Important SQL Queries, Important Database Queries, Most Common SQL Queries
Monday, May 5, 2008
Database Triggers, Types of Triggers, Syntax of Triggers
Triggers are special types of Stored Procedures that are defined to execute automatically in place of or after data modifications.
They can be executed automatically on the INSERT, DELETE and UPDATE triggering actions.
Types of triggers:
1. INSTEAD OF:
A trigger that fires before the INSERT, UPDATE, or DELETE statement is conducted.
CREATE TRIGGER trigger name
ON table name
INSTEAD OF operation AS DML statements
2. AFTER:
Tags: Database Triggers, Types of Triggers, Syntax of Triggers, Instead of trigger, After Trigger, Create Trigger
They can be executed automatically on the INSERT, DELETE and UPDATE triggering actions.
Types of triggers:
1. INSTEAD OF:
A trigger that fires before the INSERT, UPDATE, or DELETE statement is conducted.
CREATE TRIGGER trigger name
ON table name
INSTEAD OF operation AS DML statements
2. AFTER:
Stored Procedure| Database Stored Procedures| SQL Stored Procedures
A stored procedure is a set of SQL statements that can be stored in the server.
Benefits of Stored Procedures
1. Precompiled execution. SQL Server compiles each stored procedure once and then reutilizes the execution plan. This results in tremendous performance boosts when stored procedures are called repeatedly.
2. Reduced client/server traffic. If network bandwidth is a concern in your environment, you'll be happy to learn that stored procedures can reduce long SQL queries to a single line that is transmitted over the wire.
3. Efficient reuse of code and programming abstraction. Stored procedures can be used by multiple users and client programs. If you utilize them in a planned manner, you'll find the development cycle takes less time.
4. Enhanced security controls. You can grant users permission to execute a stored procedure independently of underlying table permissions.
Syntax:
CREATE PROCEDURE [procedure name] (@parameter1 type, @parameter2 type) AS
Sql statements………
BEGIN
END
…………….
GO
To declare variables:
DECLARE
Eg: DECLARE @temp int
To assign values:
SET
Eg: SET @temp = 0
To return a value:
CREATE PROCEDURE [proc name] (@p1 type, @p2 type output) AS
……
GO
Eg: Create Procedure GetAuthorsByLastName1 (@au_lname varchar(40), @RowCount int output) as select * from authors where au_lname like @au_lname; /* @@ROWCOUNT returns the number of rows that are affected by the last statement. */
select @RowCount=@@ROWCOUNT
Error Handling:
@@Error is used.
Include the SET NOCOUNT ON statement into your stored procedures to stop the message indicating the number of rows affected by a Transact-SQL statement.This can reduce network traffic, because your client will not receive the message indicating the number of rows affected by a Transact-SQL statement.
To Execute in query analyzer:
Exec [procedure name] [parameters]
To call from ASP page:
Rs.Open "exec [procedure name] [parameters]", conn
To write comments:
/* */
Tags: Stored Procedure, Database Stored Procedures, SQL Stored Procedures, Stored Procedure Syntax, Call a stored procedure from asp page, Execute a stored procedure, Error Handling in stored procedures
Benefits of Stored Procedures
1. Precompiled execution. SQL Server compiles each stored procedure once and then reutilizes the execution plan. This results in tremendous performance boosts when stored procedures are called repeatedly.
2. Reduced client/server traffic. If network bandwidth is a concern in your environment, you'll be happy to learn that stored procedures can reduce long SQL queries to a single line that is transmitted over the wire.
3. Efficient reuse of code and programming abstraction. Stored procedures can be used by multiple users and client programs. If you utilize them in a planned manner, you'll find the development cycle takes less time.
4. Enhanced security controls. You can grant users permission to execute a stored procedure independently of underlying table permissions.
Syntax:
CREATE PROCEDURE [procedure name] (@parameter1 type, @parameter2 type) AS
Sql statements………
BEGIN
END
…………….
GO
To declare variables:
DECLARE
Eg: DECLARE @temp int
To assign values:
SET
Eg: SET @temp = 0
To return a value:
CREATE PROCEDURE [proc name] (@p1 type, @p2 type output) AS
……
GO
Eg: Create Procedure GetAuthorsByLastName1 (@au_lname varchar(40), @RowCount int output) as select * from authors where au_lname like @au_lname; /* @@ROWCOUNT returns the number of rows that are affected by the last statement. */
select @RowCount=@@ROWCOUNT
Error Handling:
@@Error is used.
Include the SET NOCOUNT ON statement into your stored procedures to stop the message indicating the number of rows affected by a Transact-SQL statement.This can reduce network traffic, because your client will not receive the message indicating the number of rows affected by a Transact-SQL statement.
To Execute in query analyzer:
Exec [procedure name] [parameters]
To call from ASP page:
Rs.Open "exec [procedure name] [parameters]", conn
To write comments:
/* */
Tags: Stored Procedure, Database Stored Procedures, SQL Stored Procedures, Stored Procedure Syntax, Call a stored procedure from asp page, Execute a stored procedure, Error Handling in stored procedures
Database Indexing, Types of Index, Indexes
A database index is a copy of part of a table that is used to speed up data retrieval in a database.Indexes can be created using one or more columns, providing the basis for both rapid random lookups and efficient ordering of access to records.
Types of Index:
Clustered Index
Non-Clustered Index
Clustered Index:
A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore table can have only one clustered index. The leaf nodes of a clustered index contain the data pages.
A clustered index stores data similar to a phone directory where all people with the same last name are grouped together. SQL Server will quickly search a table with a clustered index while the index itself determines the sequence in which rows are stored in a table. Clustered indexes are useful for columns searched frequently for ranges of values, or are accessed in sorted order.
CREATE UNIQUE CLUSTERED INDEX DummyTable2_EmpIndexON DummyTable2 (EmpID)GO
Non-Clustered Index:
A non-clustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on disk. The leaf node of a non-clustered index does not consist of the data pages. Instead, the leaf nodes contain index rows.
A non-clustered index stores data comparable to the index of a text book. The index is created in a different location than the actual data. The structure creates an index with a pointer that points to the actual location of the data. Non-clustered indexes should be created on columns where the selectivity of query ranges from highly selective to unique. These indexes are useful when providing multiple ways to search data is desired.
CREATE UNIQUE NONCLUSTERED INDEX DummyTable1_empidON DummyTable1 (empid)GO
Tags: index, indexes, indexing, Database Indexing, Types of Index, Clustured Index, Non-Clustered Index, Syntax of Index, Clustured index syntax, Non clustured index syntax
Types of Index:
Clustered Index
Non-Clustered Index
Clustered Index:
A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore table can have only one clustered index. The leaf nodes of a clustered index contain the data pages.
A clustered index stores data similar to a phone directory where all people with the same last name are grouped together. SQL Server will quickly search a table with a clustered index while the index itself determines the sequence in which rows are stored in a table. Clustered indexes are useful for columns searched frequently for ranges of values, or are accessed in sorted order.
CREATE UNIQUE CLUSTERED INDEX DummyTable2_EmpIndexON DummyTable2 (EmpID)GO
Non-Clustered Index:
A non-clustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on disk. The leaf node of a non-clustered index does not consist of the data pages. Instead, the leaf nodes contain index rows.
A non-clustered index stores data comparable to the index of a text book. The index is created in a different location than the actual data. The structure creates an index with a pointer that points to the actual location of the data. Non-clustered indexes should be created on columns where the selectivity of query ranges from highly selective to unique. These indexes are useful when providing multiple ways to search data is desired.
CREATE UNIQUE NONCLUSTERED INDEX DummyTable1_empidON DummyTable1 (empid)GO
Tags: index, indexes, indexing, Database Indexing, Types of Index, Clustured Index, Non-Clustered Index, Syntax of Index, Clustured index syntax, Non clustured index syntax
Database Views| MSSQL Views| SQL Server Views| Syntax of Database Views| Types of Views
A view may be thought of as a virtual table, that is, a table that does not really exist in its own right but is instead derived from one or more underlying base table. In other words, there is no stored file that direct represents the view instead a definition of view is stored in data dictionary.
Growth and restructuring of base tables is not reflected in views. Thus the view can insulate users from the effects of restructuring and growth in the database. Hence accounts for logical data independence.
Syntax
CREATE VIEW [<> . ] view_name [ ( column [ ,...n ] ) ] [ WITH <> [ ,...n ] ] AS select_statement [ WITH CHECK OPTION ]
<> ::= { ENCRYPTION SCHEMABINDING VIEW_METADATA }
Note: Column is for statements, which contain aggregate functions
Encryption: Code View is encrypted by using this.
Schemabinding: The view is binded with the underlying table structure. Suppose you drop a column of the base table, normally the view gives an error that there is no such column name But if you specify With Schemabinding, then we will not be able to drop the column as it is being accessed by other objects.
View_MetaData: Returns the meta data information about the view.
Check Option: Suppose we create a view with a query, which has where condition. For this view, if the user tries to insert the data that does not match the query then its of no use as that is not shown in the result. So that means, we should give access only to insert records which meets the query criteria. Hence WITH CHECK OPTION is used. The result would be an error for the situation above.
A CREATE VIEW statement cannot:
Include ORDER BY clause, unless there is also a TOP clause (remember that a view is nothing else but a virtual table, why would we want to order it?)
Include the INTO keyword.
Include COMPUTE or COMPUTE BY clauses.
Reference a temporary table or a table variable.
Select statement can use multiple SELECT statements separated by UNION or UNION ALL.
Restrictions for updating data:
A view cannot modify more than one table. So if a view is based on two or more tables, and you try to run a DELETE statement, it will fail. If you run an UPDATE or INSERT statement, all columns referenced in the statement must belong to the same table.
It’s not possible to update, insert or delete data in a view with a DISTINCT clause.
You cannot update, insert or delete data in a view that is using GROUP BY.
It’s not possible to update, insert or delete data in a view that contains calculated columns.
Types:
Indexed Views: Indexed views work best for queries that aggregate or compute columns in the table. The disadvantage of indexed views is that it will slow down a query that updates data in the underlying tables.
Partitioned Views: When you need to write a join query with tables that are in different databases, then we use partitioned views.
Tags: Database Views, SQL Views, MSSQL Views, SQL Server Views, Syntax of Database Views, Types of Views, Types of database views
Growth and restructuring of base tables is not reflected in views. Thus the view can insulate users from the effects of restructuring and growth in the database. Hence accounts for logical data independence.
Syntax
CREATE VIEW [<> . ] view_name [ ( column [ ,...n ] ) ] [ WITH <> [ ,...n ] ] AS select_statement [ WITH CHECK OPTION ]
<> ::= { ENCRYPTION SCHEMABINDING VIEW_METADATA }
Note: Column is for statements, which contain aggregate functions
Encryption: Code View is encrypted by using this.
Schemabinding: The view is binded with the underlying table structure. Suppose you drop a column of the base table, normally the view gives an error that there is no such column name But if you specify With Schemabinding, then we will not be able to drop the column as it is being accessed by other objects.
View_MetaData: Returns the meta data information about the view.
Check Option: Suppose we create a view with a query, which has where condition. For this view, if the user tries to insert the data that does not match the query then its of no use as that is not shown in the result. So that means, we should give access only to insert records which meets the query criteria. Hence WITH CHECK OPTION is used. The result would be an error for the situation above.
A CREATE VIEW statement cannot:
Include ORDER BY clause, unless there is also a TOP clause (remember that a view is nothing else but a virtual table, why would we want to order it?)
Include the INTO keyword.
Include COMPUTE or COMPUTE BY clauses.
Reference a temporary table or a table variable.
Select statement can use multiple SELECT statements separated by UNION or UNION ALL.
Restrictions for updating data:
A view cannot modify more than one table. So if a view is based on two or more tables, and you try to run a DELETE statement, it will fail. If you run an UPDATE or INSERT statement, all columns referenced in the statement must belong to the same table.
It’s not possible to update, insert or delete data in a view with a DISTINCT clause.
You cannot update, insert or delete data in a view that is using GROUP BY.
It’s not possible to update, insert or delete data in a view that contains calculated columns.
Types:
Indexed Views: Indexed views work best for queries that aggregate or compute columns in the table. The disadvantage of indexed views is that it will slow down a query that updates data in the underlying tables.
Partitioned Views: When you need to write a join query with tables that are in different databases, then we use partitioned views.
Tags: Database Views, SQL Views, MSSQL Views, SQL Server Views, Syntax of Database Views, Types of Views, Types of database views
Database Joins| SQL Joins| Types of database Joins
Join actually puts data from two or more tables into a single result set.
Types:
Inner join or Equi join
Outer Join
Left outer Join
Right Outer Join
Full Outer Join
Cross Join
Self Join
Inner Join: An inner join returns all rows that result in a match.
Example: SELECT Employees.Name, Orders.ProductFROM EmployeesINNER JOIN OrdersON Employees.Employee_ID=Orders.Employee_ID
Left Outer Join: A Left join returns all rows of the left of the conditional even if there is no right column to match.
Example:SELECT Employees.Name, Orders.ProductFROM EmployeesLEFT JOIN OrdersON Employees.Employee_ID=Orders.Employee_ID
Right Outer Join: A right join will display rows on the right side of the conditional that may or may not have a match.
Example:SELECT Employees.Name, Orders.ProductFROM EmployeesRIGHT JOIN OrdersON Employees.Employee_ID=Orders.Employee_ID
Full Outer Join: Returns all the left, right (unmatched rows) and also matched rows.
Cross-Join: A cross join (or Cartesian Product join) will return a result table where each row from the first table is combined with each row from the second table. The number of rows in the result table is the product of the number of rows in each table.
Self-Join: A self-join is a query in which a table is joined (compared) to itself. Self-joins are used to compare values in a column with other values in the same column in the same table.
Example:
SELECT DISTINCT c1.ContactName, c1.Address, c1.City, c1.Region
FROM Customers AS c1, Customers AS c2
WHERE c1.Region = c2.Region
AND c1.ContactName <> c2.ContactName
ORDER BY c1.Region, c1.ContactName;
Tags: Database Joins, Sql joins, Inner join, Equi join, Outer Join, Left outer Join, Right Outer Join, Full Outer Join, Cross Join, Self Join, Types of Database Joins
Types:
Inner join or Equi join
Outer Join
Left outer Join
Right Outer Join
Full Outer Join
Cross Join
Self Join
Inner Join: An inner join returns all rows that result in a match.
Example: SELECT Employees.Name, Orders.ProductFROM EmployeesINNER JOIN OrdersON Employees.Employee_ID=Orders.Employee_ID
Left Outer Join: A Left join returns all rows of the left of the conditional even if there is no right column to match.
Example:SELECT Employees.Name, Orders.ProductFROM EmployeesLEFT JOIN OrdersON Employees.Employee_ID=Orders.Employee_ID
Right Outer Join: A right join will display rows on the right side of the conditional that may or may not have a match.
Example:SELECT Employees.Name, Orders.ProductFROM EmployeesRIGHT JOIN OrdersON Employees.Employee_ID=Orders.Employee_ID
Full Outer Join: Returns all the left, right (unmatched rows) and also matched rows.
Cross-Join: A cross join (or Cartesian Product join) will return a result table where each row from the first table is combined with each row from the second table. The number of rows in the result table is the product of the number of rows in each table.
Self-Join: A self-join is a query in which a table is joined (compared) to itself. Self-joins are used to compare values in a column with other values in the same column in the same table.
Example:
SELECT DISTINCT c1.ContactName, c1.Address, c1.City, c1.Region
FROM Customers AS c1, Customers AS c2
WHERE c1.Region = c2.Region
AND c1.ContactName <> c2.ContactName
ORDER BY c1.Region, c1.ContactName;
Tags: Database Joins, Sql joins, Inner join, Equi join, Outer Join, Left outer Join, Right Outer Join, Full Outer Join, Cross Join, Self Join, Types of Database Joins
Database Normalization| SQL Normalization
Normalization is the process of efficiently organizing data in a database.
Goals: eliminating redundant data (for example, storing the same data in more than one table) ensuring data dependencies make sense (only storing related data in a table)
Levels: 1 NF, 2NF, 3NF, BCNF (Boyce-Codd Normal Form), 4NF, 5 NF
1 NF: Eliminate duplicative columns from the same table. Create separate tables for each group of related data and identify each row with a unique column or set of columns (the primary key).
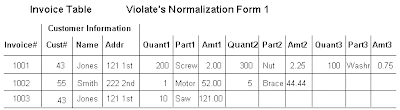
2 NF: Meet all the requirements of the first normal form. Remove subsets of data that apply to multiple rows of a table and place them in separate tables. Create relationships between these new tables and their predecessors through the use of foreign keys.
Goals: eliminating redundant data (for example, storing the same data in more than one table) ensuring data dependencies make sense (only storing related data in a table)
Levels: 1 NF, 2NF, 3NF, BCNF (Boyce-Codd Normal Form), 4NF, 5 NF
1 NF: Eliminate duplicative columns from the same table. Create separate tables for each group of related data and identify each row with a unique column or set of columns (the primary key).

2 NF: Meet all the requirements of the first normal form. Remove subsets of data that apply to multiple rows of a table and place them in separate tables. Create relationships between these new tables and their predecessors through the use of foreign keys.

3 NF: Meet all the requirements of the second normal form. Remove columns that are not dependent upon the primary key. Eg: total, average etc which can be calculated in sql query


Boyce-Codd NF:
A relation is in Boyce-Codd Normal Form (BCNF) if every determinant is a candidate key.
OR
Key attribute should not depend on a non key attribute.
Determinant: A determinant in a database table is any attribute that you can use to determine the values assigned to other attribute(s) in the same row.
Examples: Consider a table with the attributes employee_id, first_name, last_name and date_of_birth. In this case, the field employee_id determines the remaining three fields. The name fields do not determine the employee_id because the firm may have more than one employee with the same first and/or last name. Similarly, the DOB field does not determine the employee_id or the name fields because more than one employee may share the same birthday.
Candidate Key: A candidate key is a combination of attributes that can be uniquely used to identify a database record. Each table may have one or more candidate keys. One of these candidate keys is selected as the table primary key.
4 NF:
Meet all the requirements of the third normal form and BCNF.
A relation is in 4NF if it has no more than one multi-valued or multiple dependency.Consider these entities: employees, skills, and languages. An employee can have several skills and know several languages. There are two relationships, one between employees and skills, and one between employees and languages. A table is not in fourth normal form if it represents both relationships. Instead, the relationships should be represented in two tables. If, however, the attributes are interdependent (that is, the employee applies certain languages only to certain skills), the table should not be split.A good strategy when designing a database is to arrange all data in tables that are in fourth normal form, and then to decide whether the results give you an acceptable level of performance. If they do not, you can rearrange the data in tables that are in third normal form, and then re assess performance.
5NF:
(join-projection normal form)JPNF
It should be in 4NF.
No multi valued dependency exists.
Friday, April 25, 2008
SQL Server Database Backup, SQL Server Database Restore
SQL Server BACKUP and RESTORE
Restoring a database backup re-creates the database and all of its associated files that were in the database when the backup was completed.
However, any modifications made to the database after the backup was created are lost. To restore transactions made after the database backup was created, you must use transaction log backups or differential backups.
Steps:
1. Copies all of the data from the backup into the database.
2. Rolls back any incomplete transactions in the database backup to ensure that the database is consistent.
3. To prevent overwriting a database unintentionally, the restore operation performs safety checks automatically. The restore operation fails if: the database name in the restore operation does not match the database name recorded in the backup set.
4. The database named in the restore operation already exists on the server but is not the same database contained in the database backup. For example, the database names are the same, but each database was created differently.
5. One or more files need to be created automatically by the restore operation, but the file names already exist. These safety checks can be disabled if the intention is to overwrite another database.
If you restore a database on a different instance of SQL Server than the one on which the backup was created, you may need to run sp_change_users_login to update user login information.
Tags: backup, database, restore, sql server database back up, sql server database restore, MSSQL database back up, mssql database restore
Restoring a database backup re-creates the database and all of its associated files that were in the database when the backup was completed.
However, any modifications made to the database after the backup was created are lost. To restore transactions made after the database backup was created, you must use transaction log backups or differential backups.
Steps:
1. Copies all of the data from the backup into the database.
2. Rolls back any incomplete transactions in the database backup to ensure that the database is consistent.
3. To prevent overwriting a database unintentionally, the restore operation performs safety checks automatically. The restore operation fails if: the database name in the restore operation does not match the database name recorded in the backup set.
4. The database named in the restore operation already exists on the server but is not the same database contained in the database backup. For example, the database names are the same, but each database was created differently.
5. One or more files need to be created automatically by the restore operation, but the file names already exist. These safety checks can be disabled if the intention is to overwrite another database.
If you restore a database on a different instance of SQL Server than the one on which the backup was created, you may need to run sp_change_users_login to update user login information.
Tags: backup, database, restore, sql server database back up, sql server database restore, MSSQL database back up, mssql database restore
sp_change_users_login - Link users to corresponding logins
Introduction:
Although the terms login and user are often used interchangeably, they are very different. A login is used for user authentication and a database user account is used for database access and permissions validation. Logins are associated to users by the security identifier (SID). A login is required for access to the SQL Server server. The process of verifying that a particular login is valid is called "authentication". This login must be associated to a SQL Server database user. You use the user account to control activities performed in the database. If no user account exists in a database for a specific login, the user that is using that login cannot access the database even though the user may be able to connect to the SQL Server server. The single exception to this situation is when the database contains the "guest" user account. A login that does not have an associated user account is mapped to the guest user. Conversely, if a database user exists but there is no login associated, the user is not able to log into SQL Server server.
Purpose:
The sp_change_users_login procedure has a specific purpose. It’s used to identify and correct users within a database which do not have a corresponding logins.
Scenario:
When a database is restored to a different server it contains a set of users and permissions but there may not be any corresponding logins or the logins may not be associated with the same users. A mismatch may occur between the security identification numbers (SIDs) of the logins in the master database and the users in the user database. An example of when this would happen is when you are restoring a database from Production to QA.
Syntax:
sp_change_users_login [ @Action = ] 'action' [ , [ @UserNamePattern = ] 'user' ] [ , [ @LoginName = ] 'login' ] [ , [ @Password = ] 'password' ]
Action: Describes the action to be performed.
Can be one of these values:
Value: Auto_Fix
Description: Links a user entry in the sysusers table in the current database to a login of the same name in sysxlogins. You should check the result from the Auto_Fix statement to confirm that the correct link is in fact made. Avoid using Auto_Fix in security-sensitive situations.
When using Auto_Fix, you must specify user and password; login must be NULL. user must be a valid user in the current database.
Value: Report
Description: Lists the users and corresponding security identifiers (SID) in the current database that are not linked to any login.
user, login, and password must be NULL or not specified.
Value: Update_One
Description: Links the specified user in the current database to login. login must already exist. user and login must be specified. password must be NULL or not specified.
UserNamePattern:
It is the name of a SQL Server user in the current database.
LoginName:
It is the name of a SQL Server login.
Password:
It is the password assigned to a new SQL Server login created by Auto_Fix. If a matching login already exists, the user and login are mapped and password is ignored. If a matching login does not exist, sp_change_users_login creates a new SQL Server login and assigns password as the password for the new login.
How to test the scenario?
1.
Add a login to the master database, and specify the default database as Northwind:
Use master go sp_addlogin 'test', 'password', 'Northwind'
2.
Grant access to the user you just created:
Use Northwind go sp_grantdbaccess 'test'
3.
Backup the database.
BACKUP DATABASE Northwind TO DISK = 'C:\MSSQL\BACKUP\Northwind.bak'
4.
Restore the database to a different SQL Server server:
RESTORE DATABASE Northwind FROM DISK = 'C:\MSSQL\BACKUP\Northwind.bak'
The restored database contains a user named "test" without a corresponding login, which results in "test" being orphaned.
5.
Now, to detect orphaned users, run this code:
Use Northwind go sp_change_users_login 'report'
The output lists all the logins, which have a mismatch between the entries in the sysusers system table, of the Northwind database, and the sysxlogins system table in the master database.
To re-link the user:
Use Northwind go sp_change_users_login 'update_one', 'test', 'test'
Although the terms login and user are often used interchangeably, they are very different. A login is used for user authentication and a database user account is used for database access and permissions validation. Logins are associated to users by the security identifier (SID). A login is required for access to the SQL Server server. The process of verifying that a particular login is valid is called "authentication". This login must be associated to a SQL Server database user. You use the user account to control activities performed in the database. If no user account exists in a database for a specific login, the user that is using that login cannot access the database even though the user may be able to connect to the SQL Server server. The single exception to this situation is when the database contains the "guest" user account. A login that does not have an associated user account is mapped to the guest user. Conversely, if a database user exists but there is no login associated, the user is not able to log into SQL Server server.
Purpose:
The sp_change_users_login procedure has a specific purpose. It’s used to identify and correct users within a database which do not have a corresponding logins.
Scenario:
When a database is restored to a different server it contains a set of users and permissions but there may not be any corresponding logins or the logins may not be associated with the same users. A mismatch may occur between the security identification numbers (SIDs) of the logins in the master database and the users in the user database. An example of when this would happen is when you are restoring a database from Production to QA.
Syntax:
sp_change_users_login [ @Action = ] 'action' [ , [ @UserNamePattern = ] 'user' ] [ , [ @LoginName = ] 'login' ] [ , [ @Password = ] 'password' ]
Action: Describes the action to be performed.
Can be one of these values:
Value: Auto_Fix
Description: Links a user entry in the sysusers table in the current database to a login of the same name in sysxlogins. You should check the result from the Auto_Fix statement to confirm that the correct link is in fact made. Avoid using Auto_Fix in security-sensitive situations.
When using Auto_Fix, you must specify user and password; login must be NULL. user must be a valid user in the current database.
Value: Report
Description: Lists the users and corresponding security identifiers (SID) in the current database that are not linked to any login.
user, login, and password must be NULL or not specified.
Value: Update_One
Description: Links the specified user in the current database to login. login must already exist. user and login must be specified. password must be NULL or not specified.
UserNamePattern:
It is the name of a SQL Server user in the current database.
LoginName:
It is the name of a SQL Server login.
Password:
It is the password assigned to a new SQL Server login created by Auto_Fix. If a matching login already exists, the user and login are mapped and password is ignored. If a matching login does not exist, sp_change_users_login creates a new SQL Server login and assigns password as the password for the new login.
How to test the scenario?
1.
Add a login to the master database, and specify the default database as Northwind:
Use master go sp_addlogin 'test', 'password', 'Northwind'
2.
Grant access to the user you just created:
Use Northwind go sp_grantdbaccess 'test'
3.
Backup the database.
BACKUP DATABASE Northwind TO DISK = 'C:\MSSQL\BACKUP\Northwind.bak'
4.
Restore the database to a different SQL Server server:
RESTORE DATABASE Northwind FROM DISK = 'C:\MSSQL\BACKUP\Northwind.bak'
The restored database contains a user named "test" without a corresponding login, which results in "test" being orphaned.
5.
Now, to detect orphaned users, run this code:
Use Northwind go sp_change_users_login 'report'
The output lists all the logins, which have a mismatch between the entries in the sysusers system table, of the Northwind database, and the sysxlogins system table in the master database.
To re-link the user:
Use Northwind go sp_change_users_login 'update_one', 'test', 'test'
Tuesday, April 22, 2008
SQL Basics (DDL,DML,DCL,TCL,SQL Keywords, SQL Syntax)
SQL - Structured Query Language
INTRODUCTION
SQL is divided into the following:
1) Data Definition Language (DDL)
2) Data Manipulation Language (DML)
3) Data Retrieval Language (DRL)
4) Transaction Control Language (TCL)
5) Data Control Language (DCL)
DDL -- create, alter, drop, truncate, rename
DML -- insert, update, delete
DRL -- select
TCL -- commit, rollback, savepoint
DCL -- grant, revoke
Create Table Syntax:
Create table table_name (col1 datatype1, col2 datatype2 …coln datatypen)
Insert Syntax:
Case 1: insert into table_name values (value1, value2, value3 …. Valuen)
Case 2:insert into table_name(col1, col2, col3 … Coln) values (value1, value2, value3.. Valuen)
Select Syntax:
Select * from table_name -- here * indicates all columns
or
Select col1, col2, … coln from table_name
Update Syntax:
Update table_name set col1 = value1, col2 = value2 where condition
Delete Syntax:
Delete from table_name where condition
Truncate Syntax:
truncate table table_name
Drop Syntax:
Drop table table_name
Rename Syntax:
rename old_table_name to new_table_name
CONDITIONAL SELECTIONS AND OPERATORS
We have two clauses used in this
1. Where
2. Order by
1. Using Where:
select * from table_name where condition
The following are the different types of operators used in where clause:
a. Arithmetic operators
b. Comparison operators
c. Logical operators
Arithmetic operators -- highest precedence
+, -, *, /
Comparison operators
(1) =, !=, >, <, >=, <=, <>
(2) between, not between
(3) in, not in
(4) null, not null
(5) like
Logical operators
(1) And
(2) Or -- lowest precedence
(3) not
Using NULL
This will gives the output based on the null values in the specified column.
Syntax:
Select * from table_name where col is null
2. Using Order by:
This will be used to ordering the columns data (ascending or descending).
Syntax:
Select * from table_name order by col desc
By default database server will use ascending order.
If you want output in descending order you have to use desc keyword after the column.
SUB QUERIES
-- Nesting of queries, one within the other is termed as a subquery.
-- A statement containing a subquery is called a parent query.
-- Subqueries are used to retrieve data from tables that depend on the values in the table itself.
Types
1. Single row subqueries
2. Multi row subqueries
3. Multiple subqueries
4. Correlated subqueries
Single Row Sub Queries
In single row subquery, it will return one value.
Ex: select * from emp where sal > (select sal from emp where empno = 7566)
MultiRow Sub Queries
In multi row subquery, it will return more than one value. In such cases we should include operators like any, all, in or not in between the comparision operator and the subquery.
Ex:
select * from emp where sal > any (select sal from emp where sal between 2500 and 4000)
select * from emp where sal > all (select sal from emp where sal between 2500 and 4000)
Multiple Sub Queries
There is no limit on the number of subqueries included in a where clause. It allows nesting of a query within a subquery.
Ex:
select * from emp where sal = (select max(sal) from emp where sal < (select max(sal) from emp)) Correlated Sub Queries
A subquery is evaluated once for the entire parent statement where as a correlated subquery is evaluated once for every row processed by the parent statement.
Ex:
select distinct deptno from emp e where 5 <= (select count(ename) from emp where e.deptno = deptno) Using Exists:
Suppose we want to display the department numbers which has more than 4 employees,
select deptno,ename from emp e1 where exists (select * from emp e2 where e1.deptno=e2.deptno group by e2.deptno having count(e2.ename) > 4) order by deptno,ename
SET OPERATORS
Types
-- Union
-- Union all
-- Intersect
-- Minus
UNION
This will combine the records of multiple tables having the same structure.
Ex:
select * from student1 union select * from student2
UNION ALL
This will combine the records of multiple tables having the same structure but including duplicates.
Ex:
select * from student1 union all select * from student2
INTERSECT
This will give the common records of multiple tables having the same structure.
Ex:
select * from student1 intersect select * from student2
MINUS
This will give the records of a table whose records are not in other tables having the same structure.
Ex:
select * from student1 minus select * from student2
Tags: SQL Basics, SQL Introduction, DDL, DML, DRL, DCL, TCL, Database Tables, SQL Keywords
INTRODUCTION
SQL is divided into the following:
1) Data Definition Language (DDL)
2) Data Manipulation Language (DML)
3) Data Retrieval Language (DRL)
4) Transaction Control Language (TCL)
5) Data Control Language (DCL)
DDL -- create, alter, drop, truncate, rename
DML -- insert, update, delete
DRL -- select
TCL -- commit, rollback, savepoint
DCL -- grant, revoke
Create Table Syntax:
Create table table_name (col1 datatype1, col2 datatype2 …coln datatypen)
Insert Syntax:
Case 1: insert into table_name values (value1, value2, value3 …. Valuen)
Case 2:insert into table_name(col1, col2, col3 … Coln) values (value1, value2, value3.. Valuen)
Select Syntax:
Select * from table_name -- here * indicates all columns
or
Select col1, col2, … coln from table_name
Update Syntax:
Update table_name set col1 = value1, col2 = value2 where condition
Delete Syntax:
Delete from table_name where condition
Truncate Syntax:
truncate table table_name
Drop Syntax:
Drop table table_name
Rename Syntax:
rename old_table_name to new_table_name
CONDITIONAL SELECTIONS AND OPERATORS
We have two clauses used in this
1. Where
2. Order by
1. Using Where:
select * from table_name where condition
The following are the different types of operators used in where clause:
a. Arithmetic operators
b. Comparison operators
c. Logical operators
Arithmetic operators -- highest precedence
+, -, *, /
Comparison operators
(1) =, !=, >, <, >=, <=, <>
(2) between, not between
(3) in, not in
(4) null, not null
(5) like
Logical operators
(1) And
(2) Or -- lowest precedence
(3) not
Using NULL
This will gives the output based on the null values in the specified column.
Syntax:
Select * from table_name where col is null
2. Using Order by:
This will be used to ordering the columns data (ascending or descending).
Syntax:
Select * from table_name order by col desc
By default database server will use ascending order.
If you want output in descending order you have to use desc keyword after the column.
SUB QUERIES
-- Nesting of queries, one within the other is termed as a subquery.
-- A statement containing a subquery is called a parent query.
-- Subqueries are used to retrieve data from tables that depend on the values in the table itself.
Types
1. Single row subqueries
2. Multi row subqueries
3. Multiple subqueries
4. Correlated subqueries
Single Row Sub Queries
In single row subquery, it will return one value.
Ex: select * from emp where sal > (select sal from emp where empno = 7566)
MultiRow Sub Queries
In multi row subquery, it will return more than one value. In such cases we should include operators like any, all, in or not in between the comparision operator and the subquery.
Ex:
select * from emp where sal > any (select sal from emp where sal between 2500 and 4000)
select * from emp where sal > all (select sal from emp where sal between 2500 and 4000)
Multiple Sub Queries
There is no limit on the number of subqueries included in a where clause. It allows nesting of a query within a subquery.
Ex:
select * from emp where sal = (select max(sal) from emp where sal < (select max(sal) from emp)) Correlated Sub Queries
A subquery is evaluated once for the entire parent statement where as a correlated subquery is evaluated once for every row processed by the parent statement.
Ex:
select distinct deptno from emp e where 5 <= (select count(ename) from emp where e.deptno = deptno) Using Exists:
Suppose we want to display the department numbers which has more than 4 employees,
select deptno,ename from emp e1 where exists (select * from emp e2 where e1.deptno=e2.deptno group by e2.deptno having count(e2.ename) > 4) order by deptno,ename
SET OPERATORS
Types
-- Union
-- Union all
-- Intersect
-- Minus
UNION
This will combine the records of multiple tables having the same structure.
Ex:
select * from student1 union select * from student2
UNION ALL
This will combine the records of multiple tables having the same structure but including duplicates.
Ex:
select * from student1 union all select * from student2
INTERSECT
This will give the common records of multiple tables having the same structure.
Ex:
select * from student1 intersect select * from student2
MINUS
This will give the records of a table whose records are not in other tables having the same structure.
Ex:
select * from student1 minus select * from student2
Tags: SQL Basics, SQL Introduction, DDL, DML, DRL, DCL, TCL, Database Tables, SQL Keywords
Subscribe to:
Comments (Atom)